Layered Architecture Deep Dive

(이 글은 개인 의견이기 때문에, 중간중간 잘못된 내용이 있을 수 있으니 반드시 참고만 부탁드립니다)
최근 진행 중인 프로젝트는 Layered Architecture를 선택하여 패키지를 구성하고 개발하였습니다.
많은 설계 원칙들이 있지만 왜 Layered Architecture를 선택하게 되었는지, 그리고 추가적으로 어떠한 설계 원칙들을 적용하여 개발해 나가고 있는지 공유하고자 이 글을 작성하였습니다.
대상 독자는 다음과 같습니다.
- Controller, Service, Repository 형식의 패키지 분리를 하는 개발자
- 적절한 코드 품질과 일관성의 필요를 느낀 개발자
- 소규모로 구성되어 프로젝트를 진행하는 중 아키텍처 패턴을 고민하는 팀
Layered Architecture 선택 배경
Layered Architecture에 대해 소개하고 현재 진행 중인 프로젝트는 왜 해당 아키텍처 패턴을 적용하게 되었는지 기술하겠습니다.

Layered Architecture는 ‘관심사에 분리(Separation of concerns)’에 따라 시스템을 유사한 책임(관심)을 지닌 Layer로 분해하고 각각의 Layer가 하위 Layer에만 의존하도록 구성하는 아키텍처 패턴입니다.
Layered Architecture의 목적은 각 레이어들이 특정 관심사와 관련된 개체만을 포함하도록 만듦으로써 전체적인 시스템의 결합도를 낮추고, 개발자의 인지 과부하를 방지하며 재사용성을 높이고 유지보수성을 향상시키는 것입니다.
Layered Architecture에서 각 레이어의 역할이나 명칭, 개수는 문헌에 따라 차이가 있지만 대부분의 웹 애플리케이션에서 구성되는 사용자의 요청 및 응답을 담당하는 Presentation 레이어, 애플리케이션의 흐름을 제어하는 Application 레이어, 도메인의 핵심 로직을 포함하는 Domain 레이어, 상위 계층을 지원하기 위한 Infrastructure 레이어로 구성됩니다.
현재 저희의 목표는 2달 안에 애플리케이션을 완성시키는 것이며, 저희가 맡은 도메인은 비즈니스 논리가 복잡하지 않습니다. 또한 소규모(2인)로 구성된 팀이기에 개발 리소스가 많이 부족한 상황입니다.
이러한 상황 속에서 팀원과 다양한 아키텍처 패턴을 살펴보았지만, 바로 학습하여 사용하기에 무리가 있는 학습 비용이 높은 패턴들이 많았고, 잘못 적용하게 되면 코드 품질을 책임질 수 없다고 판단하게 되었습니다.
그래서 트레이드 오프를 고려한 결과 개발자에게 보다 직관적이며, 학습 비용이 높지 않고 적용하기에 무리가 없으며, 적절한 수준의 코드 품질을 가져갈 수 있는 Layered Architecture를 선택하게 되었습니다.
레이어 간 역할 정의
Layered Architecture의 기본적인 개념과 구성에 저희 팀은 몇 가지 설계 원칙을 포함하여 각각의 레이어를 다음과 같이 재구성하게 되었습니다.
Presentation 레이어
Presentation 레이어는 HTTP 요청 파라미터, Body를 Validation 하고 Application 레이어로 사용자의 요청을 위임 및 받은 응답을 반환하는 역할을 수행합니다.
추가로 함수(연산) 레벨에서의 명령과 조회의 책임을 분리하는 CQS(Command Query Separation)를 적용하여 사용자의 요청을 명시적으로 명령과 조회로 분리하여 개발하였습니다.
Command API

보통 스프링 기반의 애플리케이션에서는 HTTP 요청 파라미터 개체의 명명 규칙을 DTO(Data Transfer Object)라는 모호한 이름으로 짓는 경우가 많은데, 저희는 CQS에 착안하여 Command라는 명명 규칙을 사용하는 것이 직관적이며 명시적이라고 생각하였습니다.
Query API
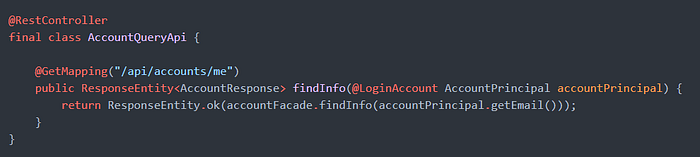
Application 레이어
Application 레이어에 대한 설명에 앞서 Layered Architecture를 적용한 코드는 아니지만, 스프링 기반의 애플리케이션을 찾아 보게 되면 아래와 같은 단일 개체 서비스를 자주 마주할 수 있었습니다.
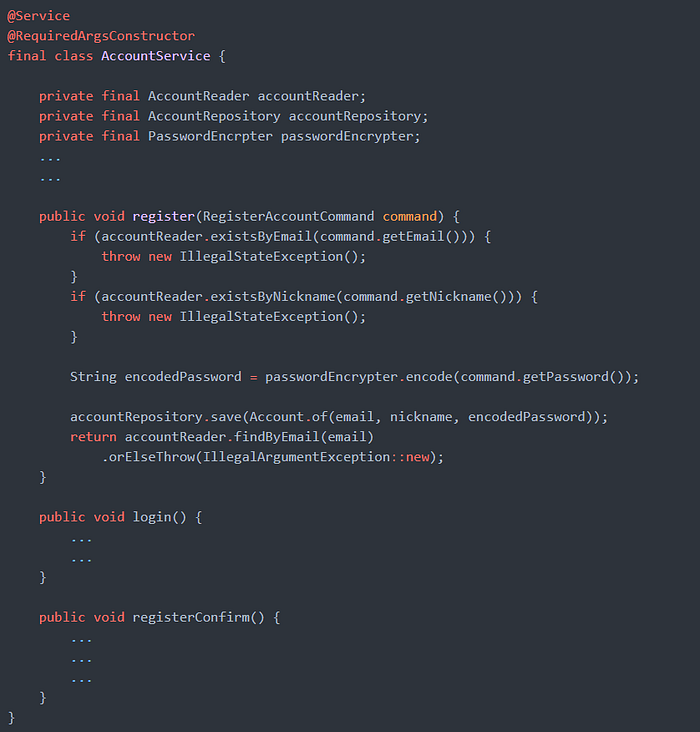
위와 같이 단일 개체 서비스를 사용한다면, 다음과 같은 단점들이 발생하게 됩니다.
- 해당 개체가 하는 역할이 너무 많아서, 복잡도가 증가합니다. 복잡도가 증가한다는 것은, 단위 테스트하기가 어렵고 단위 테스트가 어렵다는 것은 코드를 리팩토링하기가 어렵다는 뜻으로 이어집니다.
- 연관성이 적은 개체가 해당 서비스 개체에 밀집할 가능성이 높아져서, 의존하는 개체가 많아지게 됩니다. 의존하는 개체가 많아진다는 것은, 변경에 영향을 많이 받는 코드가 된다는 것을 의미하기도 합니다.
그래서 저희는 단일 개체 서비스와 같은 구조의 코드를 만들지 않기 위해서 Layered Architecture에서 설명하는 Application 레이어의 애플리케이션 흐름 제어 목적 외에도, 다음과 같은 원칙을 세워서 개발하였습니다.
- AOP를 사용한 종적 관심사와 횡적 관심사의 분리
- 도메인 모델의 도입
- 단일 개체 서비스가 아닌 단일 책임을 가지는 여러 개의 서비스로 분해 후 역할 위임
- 높은 응집도와 낮은 결합도를 갖도록 설계
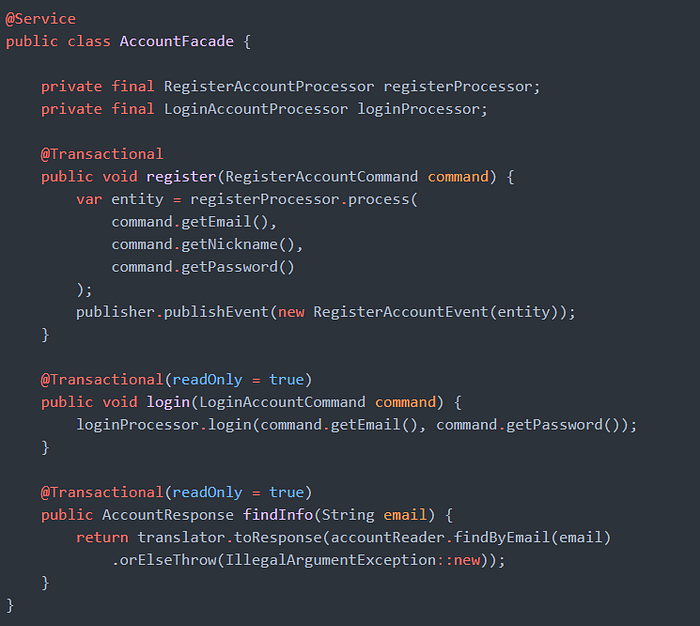
저는 다음의 내용을 참고하여, Service라는 명명 규칙보다는, Facade라는 명명 규칙이 Application 레이어의 흐름 제어 개체에 대한 책임과 직관적인 이해를 도울 수 있다고 생각하였습니다.
도메인 주도 설계에서 응용 영역에 응용 서비스는 표현 영역과 도메인 영역을 연결하는 창구인 파사드(Facade)역할을 한다. 응용 서비스는 주로 도메인 개체 간 흐름 제어만을 위해 존재하므로 단순한 형태를 갖는다.
Domain 레이어
Domain 레이어는 다음과 같은 원칙을 준수하며 개발하도록 가이드하고 있습니다.
- CQS 원칙에 따라 명령 책임과 조회 책임을 분리.
- DIP(Dependency Inversion Principle) 원칙에 따라서, 도메인 레이어의 관심사는 고수준의 비즈니스 논리를 해결해야만 하며, 저수준의 기술 구현 및 외부 인프라에 의존하지 않도록 구성.
이외에도, 다음 글에서 소개하는 SDP(Stable Dependencies Principle), SAP(Stable Abstraction Principle) 원칙을 참고하여 도메인 레이어는 추상적이어야 하며, 다른 외부 의존성을 참조하지 않도록 구성하였습니다.
아래와 같이, 현재 로그인을 처리하는 개체는 세션 기반 로그인, 토큰 기반 로그인 등 구체적인 기술에 의존하는 것이 아니라 로그인이라는 고수준의 논리만 담당하도록 인터페이스로 추상화를 하였습니다.
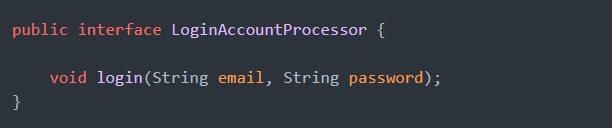
또한, 다음과 같이 도메인 모델을 사용하고, 명령과 조회를 담당하는 추상화된 개체를 정의하였습니다.
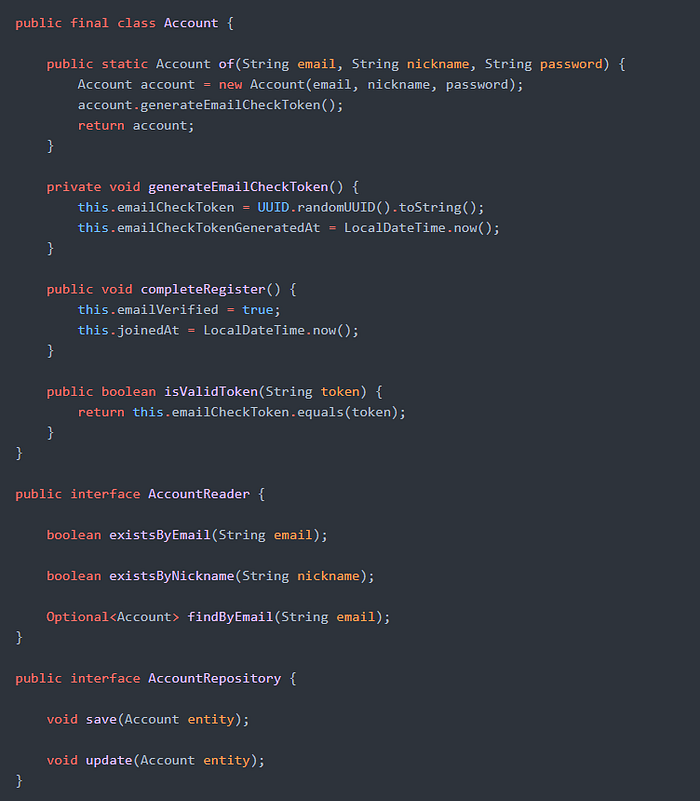
도메인 레이어를 안정적이고 추상적으로 설계하고 개발할수록, 단위 테스트, 리팩토링하기가 쉬워지며 각 개체의 퍼블릭 인터페이스를 변경하지 않는 한, 도메인 레이어를 참조하는 다른 레이어에서 변경의 여파가 발생하지 않습니다.
Infrastructure 레이어
Infrastructure 레이어는 Data Access 기술, IoC 컨테이너, 그 밖에 기술적인 작업을 수행하는 모든 개체가 포함되어 있으며, 상위 계층을 지원하는 역할을 합니다.
저희는 Infrastructure가 지원하는 역할을 기술적으로 조금더 분류해보았습니다.
- 환경 구성(Spring IoC)
- 보안(Session, JWT 등)
- Data Access(Hibernate, Mybatis, JOOQ)
- 메시징 큐(Rabbit MQ, Kafka, SQS)
- 메일(JavaMail)
다른 인프라 구성은 상관 없지만 Spring IoC와 관련해서 SpringBoot를 사용하게 되면 @SpringBootApplication 이 붙은 개체를 기준으로 하위 패키지를 Component-Scan 하기 때문에, @Component를 오용하는 경우를 많이 보았습니다.
그래서 저희는 몇가지 규칙을 세워서 Spring IoC를 사용하기로 결정했습니다.
- Domain 레이어의 의존 관계 주입 및 빈 정의는 무조건 수동으로 정의하자.
- Presentation, Application은 부분적으로 streotype annotation을 사용하자.
- 그 밖에, Infrastructure 느낌이 강한 서비스나, 구성 설정 등은 적절히 판단하여 사용하자.
위와 같은 규칙에 따라, 아래와 같이 의존 관계 구성 코드를 작성하게 되었습니다.
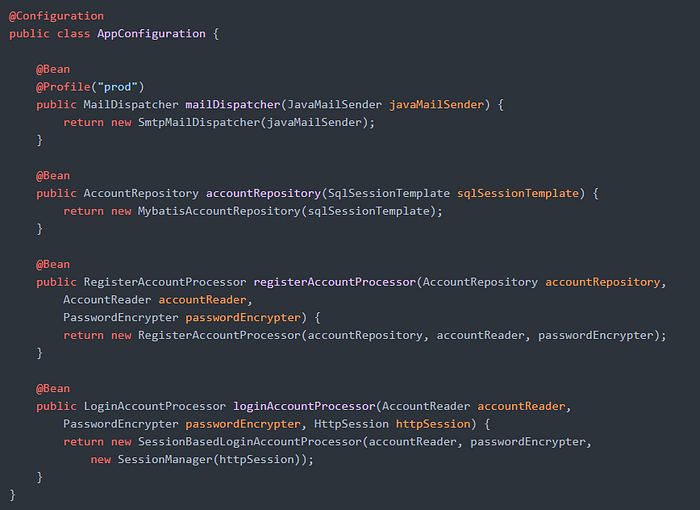
무조건적으로 수동 주입이 좋고, 자동 주입은 잘못되었다는 얘기는 아니므로 오해하지 않으셨으면 좋겠습니다. 이런 방식으로 하는 이유는 변경에 유연한 코드를 작성하기 위한 저희만의 원칙으로 생각해주시면 되겠습니다.
현재 저희는 Data Access 기술로 아래와 같이 Mybatis를 사용 중이지만, DIP 원칙이 잘 적용된 추상화 개체를 사용하여, 언제든 Hibernate나 JOOQ 등 다른 기술로 전환하여도, 도메인 레이어에 반영된 비즈니스 논리와 동작은 변하지 않습니다.
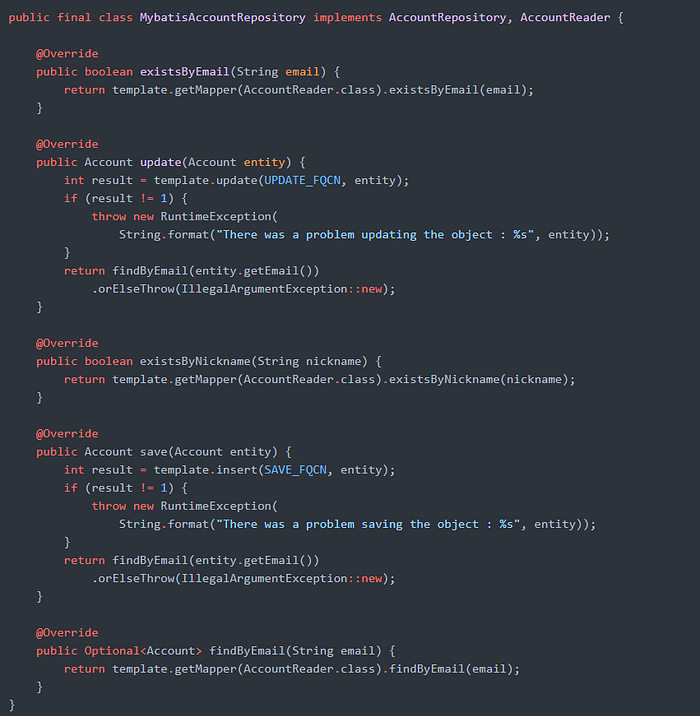
Layered Architecture의 단점
Layered Architecture를 사용함으로써, 얻는 장점들도 많지만, 다음과 같은 단점들을 발견하기도 하였습니다.
- 프로젝트 규모가 커질수록, 확장성이 떨어진다고 생각합니다.
- 레이어로 분리된 관심사 외에 다른 관심사가 발견된 경우, 패키지 분리 및 코드 배치가 난감한 경우가 발생합니다.
- 복잡한 비즈니스 논리를 해결하고 성능적 이점을 얻기는 어렵습니다.
Layered Architecture를 적용하면 좋은 경우
위와 같은 단점들이 명확하지만, 그럼에도 불구하고 다음과 같은 경우에 적용하면 좋은 아키텍처임에는 분명하다고 생각합니다.
- 프로젝트 도메인이 복잡한 논리를 포함하지 않은 경우.
- 확장성보다는 일관성을 가져가는 것이 목표인 경우.
- 소규모로 구성된 팀인 경우.
There is no silver bullet — 은탄환은 없다.
울버린, 늑대인간, 드라큘라와 같은 괴물들에게 은탄환(one seeks bullets of silver)은 한번에 무력화 시킬 수 있는 최고의 도구이다.
- Fred Brooks, 『Silver Bullet-Essence and Accidents of Software Engineering』
1986년 프레드 브룩스가 쓴 소프트웨어 공학 논문에서 은탄환의 존재에 대해 언급하며, 이와 동시에 소프트웨어 개발의 복잡성을 한번에 해소할 마법같은 솔루션(은탄환)은 없다고 선언하였습니다.
이처럼, 모든 문제를 해결해주는 아키텍처 패턴은 존재하지 않으며 개발자는 순간 순간의 상황에 맞게 트레이드 오프를 고려한 최선의 선택을 하는 것이 바람직하다고 생각합니다.
다음 글에서는, 저희 프로젝트에서 코드 품질 및 일관성을 지키기 위해서 어떠한 노력들을 기울이고 있는지 기술하겠습니다.
프로젝트
참조
